GRAG Overview#
GRAG provides an implementation of Retrieval-Augmented Generation that is completely open-sourced. Since it does not use any external services or APIs, this enables a cost-saving solution as well a solution to data privacy concerns. For more information, refer to our readme.
Retrieval-Augmented Generation (RAG)#
Retrieval-Augmented Generation (RAG) is a technique in machine learning that helps to enhance large-language models (LLM) by incorporating external data.
In RAG, a model first retrieves relevant documents or data from a large corpus and then uses this information to guide the generation of new text. This approach allows the model to produce more informed, accurate, and contextually appropriate responses. Traditionally, it uses a vector database/vector store for both retrieval and generation processes.
By leveraging both the retrieval of existing knowledge and the generative capabilities of neural networks, RAG models can improve over traditional generation methods, particularly in tasks requiring domain-specific knowledge or factual accuracy.
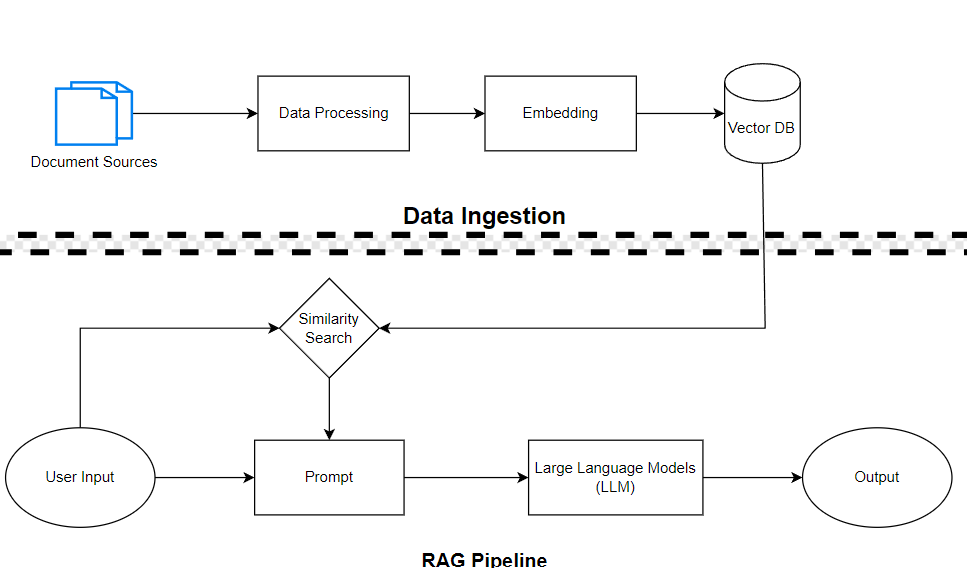
Illustration of a basic RAG pipeline#